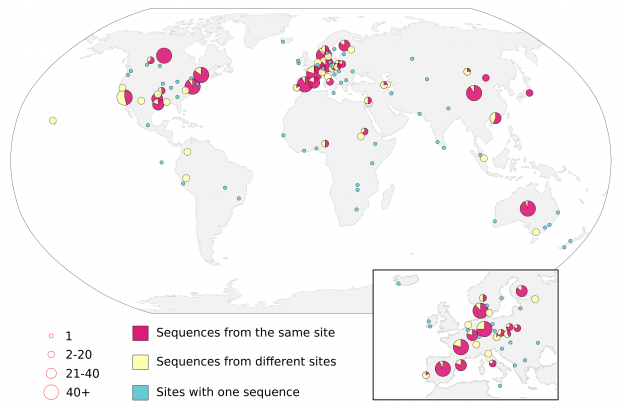
Following up from the crAssphage press and comments Dan asked me the following question:
It was interesting to hear that there are 10 times as many viruses as bacteria in the body. If you have time to answer a question, I’ve always wondered about the relative biomass of bacteria compared to human cells, and now the relative biomass of viruses compared to human cells.
Inspired by XKCD’s what-if we can use some Fermi estimation to answer this. A typical virus is about 10-19 kg. (e.g. Adenovirus which is about 50kb is 2.5 x 10-19 kg [1]). A typical bacterium, like E. coli is about 10-15 kg, and a typical human cell is about 10-12 kg.
Scientists like to say that we have ~10x more bacteria than human cells and ~10x more viruses than bacteria. In the human body there are about 37 trillion cells [2] (37 x 1012, but since we are estimating we’ll round that to 1014) . Based on these estimates we have the average human weighs about 100 kg (1014 cells x 10-12 kg) in human cells, 1 kg in bacteria (1015 cells x 10-15 kg), and 0.001 kg in viruses (1016 viruses x 10-19 kg)